Analysis of Excess Consumption in College Students by KPAG Method during the COVID-19 Pandemic
With the arrival of COVID-19, some areas are under closed management, bringing about changes in the way people consume. It also leads to the excessive consumption of some people, especially college students. In order to give early warning to unreasonable consumption behavior, this study designed KPAG algorithm to give early warning to consumption risk. Using particle swarm optimization (PSO) kernel principal component analysis (KPCA) parameter optimization, optimal polynomial kernel to delete data information, and ant colony genetic algorithm (association) clustering analysis of data dimensionality reduction, according to the consumption behavior of college students are divided into three categories, for the consumption behavior of college students to build an early warning model. Through the classification and verification experiment of real data, the results show that compared with the traditional PCA data fitting method, the accuracy of the model in this paper can reach 90%, which is more reliable than the traditional algorithm, and the accuracy of the model is improved by nearly 20%, which can be used for effective early warning.
Bin Zhao1* and Jinming Cao2
Keywords: Data Analysis; Consumption Risk; KPAG Algorithm; Early-Warning
Introduction
With the global outbreak of COVID-19 in 2019, the way people shop has partly changed. College students, as a special group of consumer groups, have the characteristics of low economic burden and high consumption power, which should be paid more attention to. At present, studies have proved that college students are more inclined to consume online than ordinary consumers [1], and online shopping festivals are an important factor affecting consumer behavior [2]. Moreover, with the closed management brought by the epidemic, the trend of college students’ online consumption and unhealthy consumption has also increased. Bollen Zoé [3] conducted a survey among Belgian college students and found that some college students consumed more alcohol during the closed management period, which required the government to pay attention and give early warning. Therefore, it is very necessary to evaluate the consumption behavior of college students and give early warning to unreasonable behaviors in the period of closed management, so as to prevent a series of campus risks such as excessive campus loans. In terms of research methods, many scholars used to establish logistic regression model to study the main factors affecting consumer consumption [4]. However, there is a high correlation between the related factors affecting college students’ consumption behavior, and in most cases, it is impossible to describe and analyze college students’ online consumption directly by using the original measurement indicators. Among many current research methods, PCA elimination is a common method to eliminate multicollinearity [5]. In view of the disadvantage that PCA cannot deal with nonlinear problems, some scholars have found that introducing kernel function for processing can obtain higher precision processing effect [6]. Some studies have established an excellent economic management model based on KPCA to solve the problem of information entanglement between data [7, 8]. Nadia Souilem [9] designed an appropriate pre-filter for the optimization of the core function of KPCA algorithm. However, all the above studies only processed the data and lacked the continuous evaluation and classification of the corresponding processed objects. In addition, KPCA still has the disadvantages of setting parameters and difficulty in evaluating and classifying indexes. Ag Abo Khalil [10] found that the optimization algorithm could obtain better results in parameter optimization of kernel function. Zhao Min [11] designed a cultural particle swarm optimization algorithm. Rongyi Li [12] used particle swarm optimization to select kernel function parameters. The above research provides ideas for parameter optimization in this paper. The establishment of academic early warning model based on KPCA [13] and fault detection model [14, 15, 16] also provides an important reference for the establishment of cluster early warning model in this study.
In this study, combined with the research content, the traditional PCA - linear regression is carried out on the consumption of evaluation model of optimization: three times by introducing kernel function solve the problem of nonlinear data processing, the introduction of optimization algorithm for the optimal kernel parameters optimization solve the defect of the parameters need to be set in combination with clustering algorithm to process the data and implement evaluation and classification of the early warning function.
KPAG Method
Aiming at the problems of the traditional consumption warning model based on PA-Logistics, such as single warning direction, poor data dimension reduction effect, multiple fitting factors and low accuracy, this paper creatively designed the KPAG method. First of all, referred to the dimensionality reduction data processing idea of the kernel method. The sample data set was established, default kernel parameters were set, and the sample set was mapped to a higher dimension by the kernel function. First reference nuclear dimension reduction of the data processing methods, we established X sample data set and design for the default nuclear s , then using the kernel function K to higher dimensional mapping of sample set, ( ) jx Φ sample data to feature space is obtained, then the principal component is obtained by principal component analysis and the sample on the principal component characteristic vector projection iµ , finally calculated feature space sample data within the class of discrete degree of w S , and discrete degree bS ’s difference value between classes. The default kernel parameters are judged according to the characteristic accumulative value of the first three principal components. If the requirements are not met, the objective function J will be established, and the difference between w S and bS will be taken as the fitness function J (s), and the particle swarm optimization algorithm will be used to iteratively solve the optimal nuclear parameters s . KPCA processing is carried out with s. Finally, by referring to the idea of ant colony clustering algorithm, the early warning objective function J (w, c) is established through characteristic parameters, the uniform two-point crossover operator is introduced to update the information matrix, and the early warning result is obtained through iterative calculation. The algorithm flow chart is shown in Figure 1.

Modeling and Derivation
In the derivation, the original consumption data set is represented by X, and xi is the K -dimensional consumption impact factor. Remember that the space of K × N dimension vector is the input space, and the nonlinear mapping Φ is used to map the data sample { } 1 2 3 , ,... X x x x = to the characteristic space H. Then, the high-dimensional
consumption data set
$$ \Phi (x) = \left\{\phi_ {1}, \phi_ {2} \dots \phi_ {3} \right\} $$
is obtained. By
default, the high-dimensional consumption data set in
the feature space has completed centralized processing,
satisfying ( ) ( ) 0 T i i x x Φ Φ =
. By PCA analysis of the high-
dimensional consumption factor, the covariance matrix
C can be calculated, where C satisfies relation V
CV λ =
After diagonalizing $C$, the consumption eigenvalue $\lambda$ of $C$ and the corresponding eigenvector $V \in H$ are obtained. Since $V \in span \left\{ \Phi(x_1), \Phi(x_2), \ldots, \Phi(x_i) \right\}$, it can be known that a group of coefficients $\alpha_1, \alpha_2, \ldots, \alpha_n$ have the following relationship:
$$V = \sum_{k=1}^{n} \alpha_j \Phi(x_j) \tag{1}$$
For the defined kernel function:
$$K : K_{ij} = \left( \Phi(x_i), \Phi(x_j) \right) = K \left( X_i, X_j \right) \quad \lambda V = CV$$ is converted to $n\lambda\alpha = K\alpha$, through the kernel function, and the kernel function $K \left( X_i, X_j \right)$ can be calculated in the original space. In order to meet the default centralization hypothesis mentioned above, the kernel matrix was adjusted to $K = K - I_n K - KI_n + I_n KI_n$ in this study, with $r$ representing the number of principal components obtained through dimensionality reduction $w_k$ representing the contribution of the extracted $k$-principal component to the data set, $\alpha_i^k$ representing the $i$-th element of the feature vector and the $k$-th principal component of data point $X$ representing $\alpha_i^k K(x_i, x)$. The first three principal component accumulation values were taken as the representative degree of the original data set. In order to optimize the kernel parameters of the introduced Gaussian kernel function $K(x, x_i) = \exp \left( -\left| x - x_i \right|^2 / \sigma^2 \right)$ and polynomial kernel function $K(x, x_i) = \left[ \left( x.x_i \right) + 1 \right]^q$, the problem was transformed into an optimization problem and PSO algorithm was introduced. There are altogether $N$ samples of consumption data $x \in K$, so the mean vector in the high-dimensional consumption data space is:
$$\mu_i = \frac{1}{N_i} \sum_{i=1}^{n} x \in K \tag{2}$$
Calculate the difference $\delta = \left| \bar{\mu}_1 - \bar{\mu}_2 \right| = \left| \eta^T \left( \mu_1 - \mu_2 \right) \right|$ between the pairwise mean values of the projection direction, calculate the discrete matrix $Sb$ between classes and the discrete $Sw$ matrix within classes:
$$\begin{cases} \bar{S}_w = \sum_{j=1}^{2} \sum_{i=N} \left( \eta^T x_i - \eta^T \bar{\mu}_j \right)^T \\ \bar{S}_b = \left( \bar{\mu}_1 - \bar{\mu}_2 \right)^2 = \left( \eta^T \mu_1 - \eta^T \mu_2 \right)^T \end{cases} \tag{3}$$
According to the requirement of consumption warning model that the first three principal components should be greater than 0.85 and the first ten principal components should be greater than 0.95, the corresponding objective function is constructed:
$$\min \sigma > 0 \tag{4}$$
$$s.t. \min J(\sigma) = \frac{\bar{S}_w}{\bar{S}_b}, \max \sum_{i=1}^{3} \alpha_i K(x_i, x)$$
Taking as fitness function $J(\sigma)$, the value range of kernel parameter $(\sigma_{\max}, \sigma_{\min})$ is determined by the limit of accumulation value of principal component in iteration. Set the number of particles $N$ inertia weight $w$ and the maximum number of iterations $T$, randomly generate the initial population and continuously update the particle position until reaching the upper limit of iteration, output the optimal nuclear parameter $\sigma$, and complete the dimension reduction of the original consumption data. After obtaining the characteristic samples, $X_{ij}$ represents the $P$ characteristic parameter in the $i$ sample, and $C_{ij}$ represents the $p$ characteristic parameter in the $j$ category of consumption behavior center. According to the ant colony genetic algorithm, ant colony design clustering target is constructed. The consumption warning model of college students is as follows:
$$\min J(w, c) = \sum_{j=1}^{m} \sum_{i=1}^{N_j} w_{ij} \left| x_{ij} - c_{ij} \right|^2 \tag{6}$$
$$c_{ij} = \sum_{i=1}^{N_j} w_{ij} x_{ij} / \sum_{i=1}^{N_j} w_{ij} (i = 1, \ldots, M; p = 1, \ldots, n) \tag{7}$$
$$w_{ij} = \begin{cases} 1, & \text{Consumer } i \text{ is the } j\text{th consumer group} \\ 0, & \text{otherwise} \end{cases} \tag{8}$$
According to the transition probability formula, the ant solution is updated and the uniform two-point crossover operator is introduced to iterate and update the information matrix. When the clustering target is reached or the maximum number of iterations is reached, the clustering results are output, the ratio of characteristic data and income level is set as the threshold, the extreme samples are tagged into the model, and then different warnings are given to the characteristics of different consumer groups after classification.
Experiment and Analysis
From July to November after the COVID-19 outbreak, a questionnaire survey was conducted among undergraduates in a university in Hubei province by random sampling. According to the consumption structure ratio of contemporary college students, the design problems include nutrition, life, clothing, entertainment, and excessive consumption, with a total of 17 consumption influencing factors.
Considering the different consumption evaluation of families with different incomes, the household income option is added to the questionnaire as one of the criteria to determine the warning interval in the following part.
A total of 89 valid papers were recovered. Four grades were determined according to the Linkert Scale method.
According to the extreme values in the questionnaire, 6 unreasonable answers were screened out, and 83 valid data were finally obtained. Part of data are shown in Table 1 below:
| Diet/ Nutrition | Snacks/Nutrition | Online shopping/ clothing | ... | Live streaming gifts /entertainment | |
|---|---|---|---|---|---|
| 1500-2000 | Less than 300 | More than 500 | 500-1000 | ... | nonuse |
| 1000-1500 | 300-600 | 200-500 | Less than 100 | ... | 0-100 |
| 1000-1500 | 300-600 | 1-200 | 100-500 | ... | 100-500 |
| ... | ... | ... | ... | ... | ... |
| 1500-2000 | 600-1000 | 1-200 | Less than 100 | ... | 0-100 |
| More than 2000 | 600-1000 | 200-500 | 100-500 | ... | nonuse |
Table 1: Consumption questionnaire survey raw data table. Source: Questionnaires collected Through data transcoding, the indicato
In order to represent the data indicators of college students’ consumption obtained in the questionnaire, Pearson correlation analysis was carried out on the data and covariance was calculated. Relevant data of various factors were obtained through Matlab programming, as shown in Table 2:
| Significant correlation factor | relevant coefficient | |
|---|---|---|
| Online shopping for clothes/clothing | Snacks and takeaway/Nutrition | 0 |
| Online shopping for skin care/clothing | Online shopping for clothes/clothing | 0.001 |
| excess consumption on Nov 11/Consumption amount | Dine together for consumption/entertainment | 0.001 |
Table 2: Data factor correlation analysis data table.
According to Table 2, it can be found that there is information entanglements among various impact factors, and the impact factors need to be dimension-reduced to reflect the consumption behavior of college students. Among all the indicators, the highest correlation with the total consumption of college students is online shopping of clothing, online skin care products and the amount of spending on Singles’ Day. It is reasonable to think that today’s online shopping culture has become an important part of contemporary university consumption and influence factors.
Table 3 is the PSO optimization parameter table. The kernel function is optimized by programming with Matlab. Set the default multinomial kernel parameter of 10 and Gaussian kernel parameter of 287 as the control group for comparison test.
| Project | particle number N | inertia weight w | acceleration sensor C | Max Iterations T | speed limit V |
|---|---|---|---|---|---|
| parameter values | 20 | 1.2 | 0.4 | 100 | 1 |
Table 3: PSO optimization algorithm parameter table.
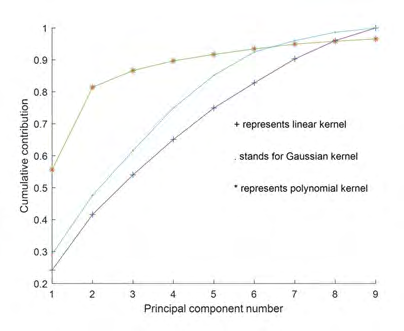
After dimension-reduction processing, it can be found that KPCA is significantly better than PCA algorithm in data processing. After optimizing the Gaussian kernel function and polynomial kernel parameters respectively, it is found that when the kernel parameter is 8, the best dimension reduction effect can be obtained. The comparison of dimensionality reduction effect before and after PSO optimization is shown in Figure 2.
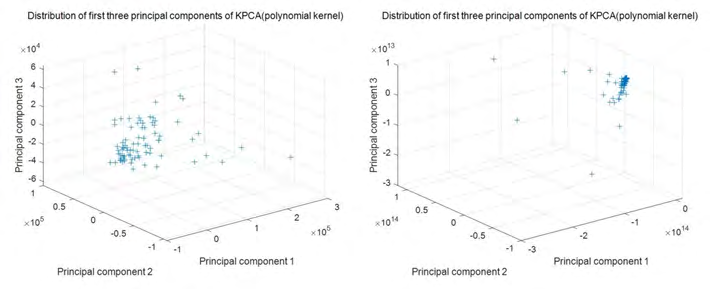
It can be seen from Figure 2 and Figure 3 that when the kernel parameter s is 8, the first three principal components of multiple linear kernel can achieve a cumulative contribution rate of 89.6%, which reaches the expectation. At the same time, the first three principal components obtained can get good aggregation effect in space, so the kernel function is considered to be the most suitable for this model.
Ant colony genetic algorithm was adopted for recognition and classification, and the maximum iteration number was set as 3000. 83 samples were trained by 100 ants under 3 classification modes, and the average training time was 152 seconds. The maximum value of the ratio between consumption amount and income was set as the threshold value. Three samples of obvious consumption amount were too high, four were normal, and three samples of online shopping consumption amount was too high were labeled.
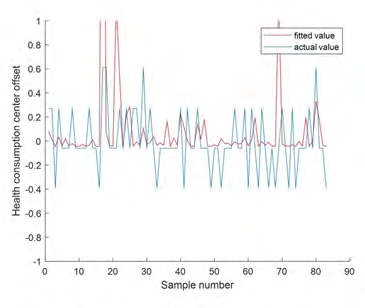
After being substituted into the model, the recognition accuracy is 80%, which meets the expected requirements. PCA- regression fitting was used to calculate the consumption fitting curve. K1, K2 and K3 were used to represent the first three principal components respectively to fit the monthly consumption amount to get the consumption function:
3 1 3 0.21 0.0969 0.4074 Y k k = − −
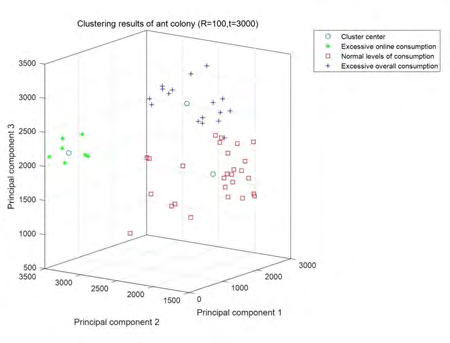
It can be seen from Figure 4 that the obtained consumption model can divide college students into three categories according to their consumption behaviors and give early warning for different consumption behaviors.
In the fitting image in Figure 5, the traditional algorithm can partially fit the original monthly total consumption, and the fitting accuracy of the traditional PCA fitting regression algorithm is 58%.Comparison effect of the algorithm is shown in Table 4.
| algorithm | Principal component contribution | Types of warning | Warning accuracy |
|---|---|---|---|
| Based on KPAG method | 91% | 3 | 80% |
| PCA- Ant Colony Clustering | 64% | 3 | 64% |
| KPCA- Linear Fitting | 80% | 2 | 71% |
| PCA- Linear Fitting | 64% | 2 | 58% |
Table 4: Comparison of algorithm effects.
Conclusion
Through the collection of relevant data and the corresponding mathematical optimization analysis, the following conclusions are drawn:
- Since the outbreak of COVID-19, online shopping of clothing, online shopping of consumer goods and the consumption amount of the Double eleven shopping days are the important influencing factors of college students’ consumption, which indicates that the current online consumption has had a significant impact on college students’ consumption behavior, which should be paid more attention to.
- Compared with the traditional PCA processing idea (Figure 3), 7 principal components need to be extracted if the standard is met. However, the method adopted in this paper can reduce the principal components to 2, and the cumulative contribution rate is 89.6%, which well maintains the data characteristics
- In this paper, the processing module of KPCA optimized by PSO can retain the features of the original data more completely and remove miscellaneous information (Figure 2). Compared with the case of no optimization, it shows a higher linear classification effect.
- Compared with the traditional algorithm, the consumption risk warning model designed in this paper based on KPAG method is richer in direction and can provide corresponding warnings for different consumption behaviors (Figure 4, Figure 5).
The accuracy of the algorithm is higher than that of the traditional algorithm, and it has better feasibility and practical value.
Conflict of Interest
We have no conflict of interests to disclose and the manuscript has been read and approved by all named authors.
Acknowledgement
This work was supported by the Philosophical and Social Sciences Research Project of Hubei Education Department (19Y049), and the Staring Research Foundation for the Ph.D. of Hubei University of Technology (BSQD2019054), Hubei Province, China.
References
-
Kuswanto H, Widyan Bima PH, Imam Safawi A (2020) Survey data on students’ online shopping behaviour: A focus on selected university students in Indonesia. Data in brief 29: 105073.
-
Qian S, Jia J, Junping Q (2020) Utilitarian or hedonic: Event-related potential evidence of purchase intention bias during online shopping festivals. Neuroscience Letters 715: 134665.
-
Bollen Z, Pabst A, Creupelandt C, Fontesse S, Lannoy S, et al. (2020) Prior drinking motives predict alcohol consumption during the COVID-19 lockdown: A cross- sectional online survey among Belgian college students. Addictive Behaviors 115: 106772-106791.
-
Chen S, Yan L (2011) Analysis on Consumption Influence Factors of Students from Guangxi University based on Order Logistic Regression Model. Journal of Guangxi Academy of Sciences 27(3): 186-189.
-
Moeller S, Pisharady PK, Ramanna S, Lenglet C, Akakaya M, et al. (2021) Noise reduction with distribution corrected (nordic) pca in dmri with complex-valued parameter-free locally low-rank processing. NeuroImage 226: 117539-117546.
-
Alsenan SA, Alturaiki IM, Hafez AM (2020) Auto-kpca: a two-step hybrid feature extraction technique for quantitative structure–activity relationship modeling. IEEE Access 9: 2466-2477.
-
GUO Yuanyuan (2014) Study on Elimination of multicollinearity Based on Kernel Principal Component Regression. Hebei United University.
-
Pan Wenyan, Wang Zongjun (2016) Research on evaluation of low carbon economic development level based on kernel principal component analysis. Finance and Economics 5(1): 55-59+91.
-
Nadia Souilem, Ilyes Elaissi, Hassani Messaoud (2017) On the use of KPCA pre-filtering for KCCA method. The International Journal of Advanced Manufacturing Technology 91: 4331-4340.
-
Abo Khalil AG (2020) Maximum power point tracking for a PV system using tuned support vector regression by particle swarm optimization. Journal of Engineering Research 8(4): 139-152.
-
Zhao Min, Yang Huixian, Ou Xunyong (2009) KPCA Feature Extraction Based on Cultural Particle Swarm Optimization. International Workshop on Intelligent Systems and Applications.
-
Li RY, Shen ZY (2010) Optimization of kernel parameters based on particle swarm optimization. Journal of Jiangnan University (Natural Science Edition) 4: 444- 447.
-
Zheng J (2015) KPCA Based Academic Early Warning Model for College Students and Its Application. North China University of Science and Technology.
-
xiao Y, Tian X (2016) Dark Background Image-denosing Based on KPCA Method. Proceedings of 2016 4th International Conference on Machinery, Materials and Information Technology Applications (ICMMITA 2016), pp: 1128-1131.
-
Yuan H, Xing S, Wang H (2015) Gearbox Fault Diagnosis Based on KPCA and Improved Ant Colony Genetic Algorithm. Measurement and Control Technology 34(06): 17-20.
-
D Fan, R Chen, J Xue, Y Zhao (2020) Quality Classification and Evaluation of Human-Machine Composite Translations of Scientific Text Based on KPCA. 2020 IEEE 3rd International Conference on Computer and Communication Engineering Technology (CCET).
- Superposition of Cryo-EM and AlphaFold Predictions of Dengue Antigen-Antibody Complexes
- Jugular-Applied Coherent Low-Level Laser Therapy Enhances Systemic Mitochondrial Metabolic Function and Antioxidant Response
- Role of OMC32 Polypeptide in Acrosin-Mediated Exocytosis during the Bovine Sperm Acrosome Reaction
- Association of Galectin-3 but not Laminin in Tamoxifen-Induced Growth Suppression in Breast Cancer MCF-7 Cells
- Effect of Different Wavelengths of Light on the Rate of Photosynthesis
- Nutritional, Therapeutic, and Environmental Effect of Oyster Mushrooms: An Editorial