Bioinformatics-Key to Drug Discovery and Development
Drug discovery and development is a complex, high risk, time consuming and potentially highly rewarding process. Pharmaceutical companies are spending millions of dollar per drug to bring it to the market. The development of a new drug requires a technological expertise, human resources and huge capital investment. It also requires strict adherence to regulations on testing and manufacturing standards before a new drug comes into market and can be used in the general population, in fact, some time it fails to come into market. All these factors just increase the cost for a new chemical entity research and development. Bioinformatics in drug designing process made positive effect on overall process and can accelerate various steps of drug designing, and reduce the cost and over all time. Current note focuses on the role of bioinformatics in drug discovery and development process.
Introduction
Drug discovery is the step-by-step process by which new candidate drugs are discovered. Traditionally, pharmaceutical companies follow well-established pharmacology and chemistry-based drug discovery approaches, and face various difficulties in finding new drugs [1]. In the highly competitive ‘‘winner takes all’’ pharmaceutical industry, the first company to patent a new chemical entity (NCE i.e., new drug candidate) for a specific treatment takes all the spoils, leaving other competitors to mostly wait for patent expirations to partake in the largesse [1]. Nowadays, therefore, Pharmaceutical companies invest heavily in all those approaches that show potential to accelerate any phase of the drug development process [2]. The increasing pressure to generate more and more drugs in a short period of time with low risk has resulted in remarkable interest in bioinformatics [3]. In fact, now there is an existence of new, separate field, known as computer- aided drug design (CADD) [4].
Drug Target Identification
One of the major thrusts of current bioinformatics approaches is the prediction and identification of biologically active candidates [2], and mining and storage of related information (Table 1). Drugs are usually only developed when the particular drug target for those drugs’ actions have been identified and studied. The number of potential targets for drug discovery process is increasing exponentially. Mining and warehousing of the human genome sequence using bioinformatics has helped to define and classify the nucleotide compositions of those genes, which are responsible for the coding of target proteins, in addition to identifying new targets that offer more potential for new drugs [5, 6]. This is an area where the human genome information is expected to play a master role [7]. Drug developers are presented with an unaccustomed luxury of choice as more genes are identified and the drug discovery cycle becomes more
| S. No | Database | Information | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | Drug bank Wishart, et al.[9] | The Drug Bank database is a blended bioinformatics and chemo informatics resource that combines detailed drug (i.e., chemical, pharmacological and pharmaceutical) data with comprehensive drug target(i.e., sequence, structure, and pathway) information | ||||||
| 2 | Therapeutic target DB Zhu, et al. [10] | The therapeutic target database (TTD) is a drug database designed to provide information about the known therapeutic protein and nucleic acid targets described in the literature, the targeted disease conditions, the pathway information and the corresponding drugs/ligands directed at each of these targets | ||||||
| 3 | STITCH Kuhn, et al. [11] | STITCH (‘search tool for interactions of chemicals’) is a searchable database that integrates information about interactions from metabolic pathways, crystal structures, binding experiments and drug-target relationships. Text mining and chemical structure similarity is used to predict relations between chemicals. Each proposed interaction can be traced back to the original data sources | ||||||
| 4 | Super Target Hecker, et al. [12] | Super Target is a database that contains a core dataset of about 7,300 drug-target relations of which 4,900interactions have been subjected to a more extensive manual annotation effort. Super Target provides tools for 2D drug screening and sequence comparison of the targets |
Table 1: Drug Target Database.
Drug Target Validation
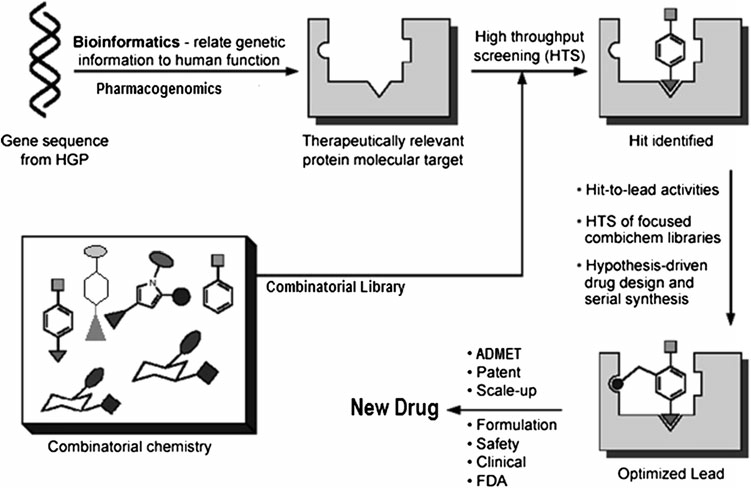
Bioinformatics also provides strategies and algorithm to predict new drug targets and to store and manage available drug target information. After the discovery of ‘‘potential’’ drug targets, there is an inappreciable need to establish a strong association between a putative target and disease of interest [7]. The establishment of such a key association provides justification for the drug development process. This process, known as target validation, is an area where bioinformatics is playing a significant role (Figure 1). Drug target validation helps to moderate the potential for failure in the clinical testing and approval phases [2].
Cost Reduction
The current high cost of drug discovery and development is a major cause for concern among pharmaceutical companies [13]. Along with increasing productivity, pharmaceutical companies also aim to reduce the high failure rate in the drug discovery process so that increased number of drugs able to hit the market [14]. The high cost of various phases of clinical trials acts as limiting factors for number of drugs, which can be developed by pharmaceutical companies, and hence selecting the compounds with the best chances for approval is critical [15]. The costs of drug discovery and development generally include total costs from discovery to approval though some studies have included the costs of failed drugs and the costs for commercialization [13, 16]. There is also a cost associated with the elongated process, beginning from discovery all the way to final approval [15, 17]. Advances in bioinformatics accelerate drug discovery process, beginning with drug target identification and validation (viz., Docking), to assay development, and virtual-high-throughput screening (v- HTS)-all with the goal of identifying new potential chemical entities. Bioinformatics provides more efficient target discovery and validation approaches, thus help to ensure that more drug candidates are successful during the approval process and making it more cost-effective [3].
Promote Novel Drug Development
There are some collateral costs that bother the pharmaceutical industry [18]. These costs include commercialization costs, litigation and drug-recall costs, and general costs to society [17, 19, 20]. Commercialization costs for new drug to be about $250 million per approved drugs, are high mainly because most ‘‘new’’ drugs approved are essentially functional replicas of drugs that already exist [16, 21]. Most of the copycat drugs are being commercialized to handle the illness for which there are drugs already; thus, there is a need of interface that can attract the attention of both physicians and patients who already have access to similar medication [22]. Bioinformatics can act as proper interface, and provides new approaches and opportunities to pharmaceutical companies to efficiently discover potential drug targets and develop novel drugs [2]. If drugs are not commercialized in competition with already existing equivalents, their commercialization costs are expected to fall significantly [23].
Barriers to Bioinformatics Progress in Drug Design Process
Bioinformatics efforts did not make any impeccable changes in the drug discovery and development process. This may be because the practice of bioinformatics is relatively new and has only attained prominence in the years following the partial completion of the Human Genome Project [24]. Till now, bioinformatics has not made any considerable impact, as projected earlier, on the cost of drugs. The pharmaceutical industry continues to witness rising costs and withdrawals of drugs from the market after they had been approved and commercialized-because of multiple documented cases of adverse drug reactions [25]. It has been observed that several pharmaceutical industries are facing drug discovery and development related challenges. These challenges range from high cost of drug discovery to the lengthy and risky trials and approval process, and some time, withdrawal of previously approved drugs from the market and the innovation gap resulting from the dogged quest for blockbuster drugs [1, 12, 13]. Bioinformatics was widely projected to strengthen the identification of drug targets [6]. The fact that these problems remain mostly unsolved, despite significant bioinformatics investments, is an indication of a larger problem [26, 27].
Conclusion
Drug designing is a very complex, expensive and time consuming process. Bioinformatics provide a huge support to overcome the cost and time context in various ways. Bioinformatics provides wide range of drug-related databases and software, which can be used for various purposes, related to drug designing and development process. Bioinformatics is still in their developmental phase and presently facing some hurdles, they show enough potential to help drug development process in near future.
References
-
Iskar M, Zeller G, Zhao XM, van Noort V, Bork P (2012) Drug discovery in the age of systems biology: the rise of computational approaches for data integration. Curr Opin Biotechnol 23(4): 609-616.
-
Whittaker P (2003) What is the relevance of bioinformatics to pharmacology? Trends Pharmacol Sci 24(8): 434-439.
-
Ortega SS, Cara LC, Salvador MK (2012) In silico pharmacology for a multidisciplinary drug discovery process. Drug Metabol Drug Interact 27(4): 199-207.
-
Speck Planche A, Cordeiro MN (2012) Computer- aided drug design, synthesis and evaluation of new anti-cancer drugs. Curr Top Med Chem 12(24): 2703- 2704.
-
Chen YP, Chen F (2008) Identifying targets for drug discovery using bioinformatics. Expert Opin Ther Targets 12(4):383-389.
-
Katara P, Grover A, Kuntal H, Sharma V (2011) In silico prediction of drug targets in vibrio cholerae. Protoplasma 248(4): 799-804.
-
Yamanishi Y, Kotera M, Kanehisa M, Goto S (2010) Drug-target interaction prediction from chemical, genomic and pharmacological data in an integrated framework. Bioinformatics 26(12): 246-254.
-
Loh M, Soong R (2011) Challenges and pitfalls in the introduction of pharmacogenetics for cancer. Ann Acad Med Singap 40(8): 369-374.
-
Wishart DS, Knox C, Guo AC, Cheng D, Shrivastava S, et al. (2008) DrugBank: a knowledgebase for drugs, drug actions and drug targets. Nucleic Acids Res 36: 901-906.
-
Zhu F, Shi Z, Qin C, Tao L, Liu X, et al. (2012) Therapeutic target database update 2012: a resource for facilitating target-oriented drug discovery. Nucleic Acids Res 40: 1128-1136.
-
Kuhn M, Szklarczyk D, Franceschini A, Campillos M, von Mering C, et al. (2010) STITCH 2: an interaction network database for small molecules and proteins. Nucleic Acids Res 38: 552-556.
-
Hecker N, Ahmed J, von Eichborn J, Dunkel M, Macha K, et al. (2012) Super target goes quantitative: update on drug-target interactions. Nucleic Acids Res 40: 1113-1117.
-
Adams CP, Brantner VV (2010) Spending on new drug development. Health Econ 19(2): 130-141.
-
Tsaioun K, Bottlaender M, Mabondzo A (2009) Alzheimer’s Drug Discovery Foundation ADDME- avoiding drug development mistakes early: central nervous system drug discovery perspective. BMC Neurol 9: S1.
-
Tamimi NA, Ellis P (2009) Drug development: from concept to marketing! Nephron Clin Pract. 113(3): 125-131.
-
Gilbert J, Henske P, Singh A (2003) Rebuilding Big Pharma’s Business Model. In vivo Business and Medicine Report 21: 10.
-
Klein DB, Tabarrok A (2003) The drug discovery, development and approval process.
-
Collier R (2009) Rapidly rising clinical trial costs worry researchers. CMAJ 180(3): 277-278.
-
Liang BA, Mackey T (2011) Direct-to-consumer advertising with interactive internet media: global regulation and public health issues. JAMA 305(8): 824-825.
-
Rawlins MD (2004) Cutting the cost of drug development? Nat Rev Drug Discov 3(4): 360-364.
-
Dickson M, Gagnon JP (2004) Key factors in the rising cost of new drug discovery and development. Nat Rev Drug Discov 3(4): 417-429.
-
Meyers S, Baker A (2001) Drug discovery: an operating model for a new era. Nat Biotechnol. 19(8): 727-730.
-
Simoens S (2011) Pricing and reimbursement of orphan drugs: the need for more transparency. Orphanet J Rare Dis 6: 42.
-
Lindpaintner K (2002) The impact of pharmacogenetics and pharmacogenomics on drug discovery. Nat Rev Drug Discov 1(6): 463-469.
-
Shin J (2012) Clinical pharmacogenomics of warfarin and clopidogrel. J Pharm Pract 25(4): 428-438.
-
Dhaliwal B, Chen YW (2009) Computational resources for protein modelling and drug discovery applications. Infect Disord Drug Targ 9(5): 557-562.
-
Du QS, Huang RB (2012) Recent progress in computational approaches to studying the M2 proton channel and its implication to drug design against influenza viruses. Curr Protein Pept Sci 13(2): 205- 210.
- Acido Labile or Gastro Irritant Apis and Enteric Release in Galenic Practice: An Overview
- A Study on Knowledge, Attitude and Practice of Hand Hygiene among Healthcare Professionals at a Tertiary Care Hospital, India
- Influence of Inoculum Concentration on In Vivo Incubation Period of Emmia lacerata, Pathogenesis and Management of Wilt in Pepper (Capsicum annuum L.)
- Vanilla’s Chemistry
- Marine Anti-Cancer Compounds and Adverse Effects of Global Warming on Oceans: An Overview
- Serological Investigation of Chikungunya Virus Antibody among Malaria-Suspected Febrile Patients in Some Healthcare Facilities in Rivers State