Machine Learning Applications in Drug Discovery and Development
Machine learning has emerged as a powerful tool in the field of drug discovery and development, revolutionizing the way pharmaceutical research is conducted. This abstract provides a concise overview of the key applications and impacts of machine learning in this domain. Drug discovery and development is a complex, time-consuming, and costly process that traditionally relies on trial-and-error experimentation. Machine learning, with its ability to analyze vast datasets and extract meaningful insights, has significantly accelerated and optimized various aspects of this process. One crucial application of machine learning in drug discovery is the prediction of potential drug candidates. Machine learning models can also aid in the identification of biomarkers for diseases, enabling more targeted drug development. In the clinical trial phase, machine learning algorithms assist in patient selection, monitoring, and optimization of trial protocols. Predictive models can identify patient subpopulations most likely to respond to a particular treatment, leading to more efficient trials and better patient outcomes. Additionally, machine learning has streamlined drug repurposing efforts by identifying existing drugs with potential new applications. This approach has the potential to save significant time and resources by leveraging existing safety and efficacy data. Furthermore, machine learning enhances the drug development pipeline by optimizing drug formulation and dosage, predicting adverse reactions, and assisting in regulatory compliance. While machine learning offers tremendous promise in drug discovery and development, it also presents challenges related to data quality, model interpretability, and regulatory approval. Addressing these challenges will be crucial for maximizing the potential of machine learning in the pharmaceutical industry.
Introduction
Machine Learning is a subset of artificial intelligence that focuses on the development of algorithms and models that allow computers to learn from and make predictions or decisions based on data without being explicitly programmed. It involves training machines to recognize patterns or relationships within data and use that knowledge to perform specific tasks or make predictions.AI is the broader concept of creating intelligent agents that can mimic human intelligence, while ML is a subset of AI that specifically deals with the development of algorithms and models that enable machines to learn from data and make decisions based on that learning. ML is a critical component of AI, as it provides the techniques and methods for machines to acquire knowledge and improve their performance over time.
The field of drug discovery and development has long been characterized by its complexity, high costs, and the arduous journey from laboratory experimentation to clinical deployment. However, in recent years, a trans-formative force has emerged to reshape this landscape: machine learning. Machine learning, a sub field of artificial intelligence, has ushered in a new era in pharmaceutical research by revolutionizing the way scientists identify potential drug candidates, optimize clinical trials, and enhance various aspects of the drug development pipeline. Historically, drug discovery often relied on a laborious process of trial and error, where scientists screened thousands of compounds to find potential drug candidates. This approach was not only time-consuming but also costly, with many promising compounds failing to progress through the rigorous testing and regulatory hurdles required for approval [1].
Machine learning, with its capacity to analyse massive datasets, extract meaningful patterns, and make predictions, has introduced unprecedented efficiencies into this field. Through the power of algorithms, statistical models, and computational techniques, machine learning has enabled researchers to navigate the complex molecular landscape of drug discovery and development with remarkable precision. In this comprehensive exploration of “Machine Learning Applications in Drug Discovery and Development,” we delve into the myriad ways in which machine learning is reshaping pharmaceutical research. We will uncover how machine learning models can predict molecular interactions, identify potential drug targets, optimize clinical trial designs, and even repurpose existing drugs for new therapeutic applications. Additionally, we will examine the ethical considerations and regulatory challenges that come hand in hand with the integration of machine learning into drug development. While this technology offers tremendous promise, it also raises questions about data privacy, model interpret ability, and the evolving landscape of drug approval and safety. In an era defined by the relentless pursuit of innovative solutions to complex healthcare challenges, machine learning stands as a beacon of hope, guiding us towards a future where drug discovery and development are faster, more efficient, and more accessible than ever before.
Drug Development
Drug development is a process of bringing a new drug or medical device to market. It is divided into four main phases such as drug discovery, preclinical studies, clinical development and market approval.
Current Context in Drug Development
New drug development is the time consuming and expensive process. Moreover in order to ensure both the patients safety and drug effectiveness, Prospective drugs has to undergo competitive and long procedure.
Drug development majorly of four stages Called phases Figure
Drug development majorly of four stages Called phases Figure 1. • Phase Zero Comprises basic research are drug discovery and pre-clinical test. • The last three Stages are Clinical trials: Study of dose toxicity. Short lived Side effects, And Kinetic relationship (Phase-1); Determination of drug performance (Phase -2); Comparison of the molecule to the Standard of Care (Phase -3); Post drug marketing Surveillance (Phase-4).
This process takes at least 5 years to be completed and can last up to 15 years.

The Future of Drug Development
This Transform the pharmaceutical industry in this span of 10 years. Many of the pharmaceutical companies faced productivity issues, mainly in case of number Approved molecules, with regard to the number of drug Candidates. An expensive way to improve this issue might be to automate some important but repetitive data processing and analysis task, more especially through robotics and Machine learning methods. Then this lead to exoculate drug development process as might be computationally thus automatically, performed and less prone to human related technical mistakes [2].
ML methods involvement into drug development process lead to;
- Decrease drug development cost and time.
- Make therapies more patients Orientated.
- As the easier integration of multi view data might allow implementation or Enhancement of precision medicine technics.
Various Fields in Drug Discovery and Development
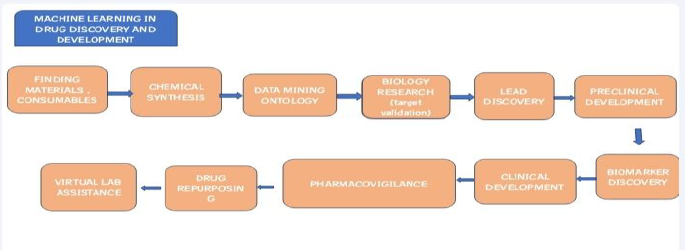
Machine Learning Methods to Drug Discovery
Through the improvement of ML techniques and the gathering of pharmacological data, AI innovation has a high importance in drug design. The core of AI lies in turning medical data into studies like repeatable approaches rather than depending on any speculative enhancements. Random Forest, Naive Bayesian Classification (NBC), Multiple Linear Regression (MLR), Logistic Regression (LR), Linear Discriminant Analysis (LDA), Probabilistic Neural Networks (PNN), Multi-Layer Perceptron (MLP), Support Vector Machine (SVM), and other approaches are generally taken into consideration in the context of machine learning (ML). AI developments are specifically applied as a deep learning technique for drug design in order to improve capabilities in feature extraction and feature generalization [2, 3].
Traditional machine learning models perform many designed features manually, but deep learning approaches will automatically accelerate different features through readily available initialized data because multi-layer feature extraction techniques are used to transform simple features into complex features. Utilizing deep learning techniques has the benefit of recovering more precise findings due to the minimal quantity of generalization errors present. Different deep learning approaches include CNN, RNN, Auto Encoder, DNN, and RBN. LeCun, et al. and Anger M, et al. and Schmid H, provide summaries of deep learning algorithms, while Good fellow, et al. provides thorough information about deep learning approaches that are available in deep learning literature.
Numerous AI algorithms are used to analyse and forecast data in the drug discovery and development process.
Drug Design Applications
The drug discovery is further divided into subcategories based on the tasks that machine learning (ML) applications are used for, such as target identification, hit discovery, hit to lead, and lead optimization strategies. The methods for drug design rely on databases, which are created using various ML algorithms. The exact training, validation, and use of machine learning (ML) algorithms in the age of drug development produce an enthusiastic result by simplifying challenging, error-prone methods. To cut down on time and manual intervention, ML approaches are now used in the majority of drug design procedures.
The best example is QSAR, where De novo design techniques have taken the place of the massive data collecting and training of datasets that were once deemed rate-limiting phases in establishing the ligand-based virtual screening protocols.
ML Algorithms Used in Drug Discovery
Drug development has significantly advanced through the use of ML algorithms. The use of multiple ML algorithms in drug discovery has extensively benefitted pharmaceutical businesses. In order to predict the chemical, biological, and physical properties of compounds in the context of drug development, ML algorithms have been applied to construct a variety of models. All phases of the drug discovery process can benefit from the use of ML algorithms. For instance, ML algorithms have been used to uncover novel medication uses, forecast drug-protein interactions, identify drug efficacy, assure the presence of safety biomarkers, and enhance molecular bioactivity. Random Forest (RF), Naive Bayesian (NB), and support vector machine (SVM), among other ML techniques, have been frequently used in the drug discovery process [4, 5].
The methods and algorithms used in ML are not a homogeneous, homogeneous subset of AI. ML algorithms can be divided into two categories: supervised learning and unsupervised learning. In supervised learning, labels for newly collected data are determined using training examples with predefined labels. Unsupervised learning identifies patterns in a collection of samples without the use of sample labels. Prior to recognizing patterns in high- dimensional data, the data are typically translated into a lower dimension using unsupervised learning methods. Dimension reduction is beneficial because the identified pattern may be more easily understood and unsupervised learning is more effective in a reduced dimension space. Integrating supervised and unsupervised learning to create semi-supervised reinforcement learning, which can be used for a variety of purposes.
All stages of drug discovery now systematically rely on this investigation, which is supported by machine learning (ML) methods and integrated databases through multiple software/web tools (Figure 2) Applications of repositioning, target identification, small molecule discovery, synthesis, etc. have demonstrated the value of new data analytics ability to synergize with traditional methodologies and existing ideas to develop unique hypotheses and models. Multidimensional information is produced in the disciplines of medicine and multiomics. The data is frequently inconsistent and comes from a variety of sources. The challenges of analyzing and interpreting multidimensional data may be alleviated by using ML techniques, such as generalized linear models using NB. Regression, clustering, regularization, neural networks (NNs), decision trees, dimensionality reduction, ensemble approaches, rule-based methods, and instance-based methods are other ML models and techniques frequently employed in these analysis fields.
Random Forest (RF): RF is an efficient method that was specifically created for huge datasets with several characteristics. It simplifies by removing outliers and classifies and designates datasets based on the relative features classified for the algorithm in consideration. According to data collected from numerous databases, it is frequently trained for accessibility, huge inputs, and variables. It helps in a variety of situations, like attributing missing data, managing outliers, and estimating characteristics for grouping. A group of uncorrelated decision trees, each of which is in charge of making one prediction, make up the mathematical process that underlies RF. The most popular choice is deemed to be the most appropriate. Naive Bayesian (NB): NB algorithms are a subset of supervised learning techniques that have evolved into a crucial tool for categorization in predictive modelling. According to the input characteristics, factor correlation, and dimensionality of the data, standard NB algorithms can be within the most efficient techniques for categorizing dataset features. It is uncertain to what extent NB works in relation to decision tree algorithms for text mining. These methods improve the precision of data sets that are recovered, which typically come from massive, chaotic sources.
Support Vector Machine (SVM): SVMs are supervised machine learning algorithms that divide compounds into classes depending on the feature selection by constructing a hyperplane. To create an endless number of the hyperplanes, the process makes use of the class similarities. For linear data, it trains by creating classes made up of compounds based on certain features and then projects those classes into the space of chemical features. A hyperplane is an illustration of an ideal hyperplane that may be used to categorize data points by defining decision boundaries in N dimensional space (N is the number of characteristics). Limitations: Drug discovery depends significantly on machine learning methods. These techniques improve productivity and explore thousands of possibilities that are not feasible without technology. Earlier stated, algorithms are acquired utilizing inputted data, however this method has several limitations. Even though ML has been around for a while, the newly identified biological pathways and targets are still novel. There might not be a lot of extrapolated data since there is not be enough information about the particular protein of interest. The Free Energy Perturbation technique is a platform for generating biological data about the protein based on computational screening. Although not all of the information is taken from a wet lab, rather computer generated predictions are used the data obtained using this method is used to train algorithms.
Deep Learning (DL) Methods
In almost all scientific and technological sectors, DL algorithms are considered as one of the most cutting edge areas of research and development. A key underlying element of deep learning (DL) and the ongoing success brought by AI- based integration of conventional approaches is the rebirth of artificial NNs from their old hypothesized and projected applications into executable algorithms. Computational models may obtain an abstraction of multidimensional data through the use of DL methods.
Ml Model Selection Concept
The objective of a good Machine learning Model is:
- To generalize well from the Training data to the Test Data at hand.
- Every technique has various existing methods, which can differ in prediction accuracy, training speed, and the number of variables they can handle.
Model over fitting shows a negative impact on the performance of the model on new data by learning some of the unusual features of the training data apart from the signals in turn incorporating these into the model.
Model under fitting refers to a model that neither models the training data nor generalizes to new data.
Limitation of overfitting can be done by applying resampling methods or by holding back part of the training data to use as a validation data set. Several software libraries are now available for high-performance mathematical computation across a variety of hardware platforms (central processing units CPUs), GPUs, and tensor processing units (TPUs), and from desktops to clusters of servers.
Drug Discovery Problems
In drug development and discovery, various clinicians and specialists faced hurdles toward target validation, computational pathology data, and identification of prognostic biomarkers in clinical preliminaries.
Target validation
- By regulating the molecular target activity, drugs can be developed through the utilization of ultimate methodologies in drug discovery for altering the infection site.
- For initiating the program in drug development, target identification requires a therapeutic hypothesis for modulating target regulation in the outcome of the infection site.
- Machine learning approaches are used in target identification due to the increment of data driven target identification experiments.
- The first step in target identification is recognizing casual confederation between disease and target.
Prognostic biomarkers
Using a machine learning approach, biomarker discovery is used to improve clinical trial performance by differentiating drugs and understanding drug mechanisms for reasonable patients.
It consumes a lot of time and cost in the final stages of clinical trials. To avoid this issue, it is needed to apply, build, and validate predicted models in the early stages of clinical trials.
The usage of ML algorithms allows for predicting translational biomarkers in preclinical data assortment.
Challenges
The majority of the difficulties in drug discovery can be resolved by applying machine learning techniques. Some of the issues are presented below along with potential solutions:
- Various ML techniques caused accurate results despite a few parameters and structures causing issues throughout the training phase. The specific method cannot meet the accuracy and local optimum, especially when there is not enough data during the training phase.
- The solution to this problem is to design a deep belief architecture, an unsupervised pretrained model that uses improved parameters to produce outcomes more effectively.
- Another difficulty in drug research is the transparency problem. Due to the ambiguity of decision-making in various classification methods. To evaluate the results of medication development, many mechanisms must be understood. This makes it more helpful in identifying new drug targets and the numerous assembled aspects required to boost interpretability.
- A wide range of processes, including SVM, MLR, RF, and deep learning algorithms, can be used in the creation of new drugs to understand and interpret the results. In order to create optimism about interpretability, it becomes more helpful in identifying novel drug targets and numerous assembled features.
- There are several sources that provide access to integrated data, particularly in the ‘omics’ area. The challenge is increasing day by day due to the expansion of the data as well as the significant heterogeneity in the pharmaceutical industry (Searls).
Conclusion
We conclude that, the integration of machine learning into drug discovery and development represents a ground breaking shift in the pharmaceutical industry. These advanced algorithms have demonstrated their capacity to mine vast data sets, accelerate drug candidate identification, and optimize clinical trials. With the potential to reduce costs, expedite timelines, and pave the way for personalized medicine, machine learning applications hold immense promise. However, as we navigate this Trans formative landscape, ethical and regulatory considerations must remain at the forefront. Collaborative efforts between researchers, industry leaders, and regulators will be pivotal in ensuring the safe and effective adoption of these technologies. ML is a powerful technique for identifying hidden patterns in complex datasets. In the coming years, machine learning will likely continue to reshape the drug development process, ultimately leading to more innovative treatments and improved healthcare outcomes for patients around the world.
ML applications are paving the way for algorithm- enhanced data query, analysis, and generation. ML techniques in drug development regions and health service centres have encountered numerous conflicts, especially in image analysis and omics data. As such, we expect to see increasing numbers of applications for well-defined problems across the industry in the coming years.
References
-
Ahmet SR, Heval A, Maria JM, Rengul CA, Volkan A, et al. (2019) Recent applications of deep learning and machine intelligence on in silico drug discovery: methods, tools and databases. Briefings in Bioinformatics 20(5): 1878- 1912.
-
Jessica V, Clark D, Paul C, Ian D, Edgardo F, et al. (2019) Applications of machine learning in drug discovery and development. Nat Rev Drug Discov 18(6): 463-477.
-
Clémence R, Emilie K, Andrée DD (2020) Machine learning applications in drug development. Computational and Structural Biotechnology Journal 18: 241-252.
-
Lauv P, Tripti S, Xiuzhen H, David WU, Shanzhi W (2020) Machine Learning Methods in Drug Discovery. Computational Methods in Drug Design and Food Chemistry 25(22): 5277
-
John WC (2020) Applications of Machine Learning in Drug Discovery I: Target Discovery and Small Molecule Drug Design. Artificial Intelligence in Oncology Drug Discovery and Development.
- Acido Labile or Gastro Irritant Apis and Enteric Release in Galenic Practice: An Overview
- A Study on Knowledge, Attitude and Practice of Hand Hygiene among Healthcare Professionals at a Tertiary Care Hospital, India
- Influence of Inoculum Concentration on In Vivo Incubation Period of Emmia lacerata, Pathogenesis and Management of Wilt in Pepper (Capsicum annuum L.)
- Vanilla’s Chemistry
- Marine Anti-Cancer Compounds and Adverse Effects of Global Warming on Oceans: An Overview
- Serological Investigation of Chikungunya Virus Antibody among Malaria-Suspected Febrile Patients in Some Healthcare Facilities in Rivers State